Normalizing genomic signals
Pierre-Luc Germain
Lab of Statistical Bioinformatics, University of Zürich;D-HEST Institute for Neuroscience, ETH Zürich, SwitzerlandSource:
vignettes/normalization.Rmd
normalization.RmdAbstract
This vignette covers the functions for normalizing genomic
signals. Since this is illustrated with visualization, it is
recommended that you read the bam2bw and
multiRegionPlot vignettes first.
Introduction
epiwraps includes two ways of calculating normalization
factors: either from the signal files (e.g. bam or bigwig files), which
is the most robust way and enables all options, or from an
EnrichmentSE object (see the
multiRegionPlot vignette for an intro
to such an object) or signal matrices. In both cases, the logic is the
same: we estimate normalization factors (mostly single linear scaling
factors, although some methods involve more complex normalization), and
then apply them to signals that were extracted using
signal2Matrix().
Applying normalization factors when generating the bigwig files
It is possible to also directly use computed normalization factors
when creating bigwig files. By default, the
bam2bw() function scales using
library size, which can be disabled using scaling=FALSE.
However, it is also possible to pass the scaling argument a
manual scaling factor, as computed by the functions described here. In
this vignette, however, we will focus on normalizing signal
matrices.
Obtaining normalization factors for a set of signal files
The getNormFactors() function can be used to estimate
normalization factors from either bam or bigwig files. The files cannot
be mixed (bam/bigwig), however, and it is important to note that
normalization factors calculated on bam files cannot be applied to
data extracted from bigwig files, or vice versa, because the bigwig
files are by default already normalized for library size. If needed,
however, getNormFactors() can be used to apply the same
method to both kind of files.
Normalization methods
Simple library size normalization, as done by bam2bw(),
is not always appropriate. The main reasons are 1) that different
samples/experiments can have a different signal-to-noise ratio, with the
result that more sequencing is needed to obtain a similar coverage of
enriched region; 2) that there might be global differences in the amount
of the signal of interest (e.g. more or less binding, globally, in one
cell type vs another); and 3) that there might be differences in
technical biases, such as GC content. For these reasons, different
normalization methods are needed according to circumstances and what
assumptions seem reasonable. Here is an overview of the normalization
methods currently implemented in epiwraps via the
getNormFactors() function:
- The ‘background’ or ‘SES’ normalization method (they are synonyms here) assumes that the background noise should on average be the same across experiments (Diaz et al., Stat Appl Gen et Mol Biol, 2012), an assumption that works well in practice and is robust to global differences in the amount of signal when there are not large differences in signal-to-noise ratio.
- The ‘MAnorm’ approach ( Shao et al., Genome Biology 2012) assumes that regions that are commonly enriched (i.e. common peaks) in two experiments should on average have the same signal in the two experiments.
- The ‘enriched’ approach assumes that enriched regions are on average similarly enriched across samples. Contrarily to ‘MAnorm’, these regions do not need to be in common across samples/experiments. This is not robust to global differences.
- The ‘top’ approach assumes that the maximum enrichment (after some trimming) in peaks is the same across samples/experiments.
- The ‘S3norm’ (Xiang et al., NAR 2020) and ‘2cLinear’ methods try to normalize both enrichment and background simultaneously. S3norm does this in a log-linear fashion (as in the publication), while ‘2cLinear’ does it on the original scale.
The normalization factors can be computed using
getNormFactors() :
suppressPackageStartupMessages(library(epiwraps))
# we fetch the path to the example bigwig file:
bwf <- system.file("extdata/example_atac.bw", package="epiwraps")
# we'll just double it to create a fake multi-sample dataset:
bwfiles <- c(atac1=bwf, atac2=bwf)
nf <- getNormFactors(bwfiles, method="background")## Comparing coverage in random regions...
nf## atac1 atac2
## 1 1In this case, since the files are identical, the factors are both 1.
Some normalization methods additionally require peaks as input, e.g.:
peaks <- system.file("extdata/example_peaks.bed", package="epiwraps")
nf <- getNormFactors(bwfiles, peaks = peaks, method="MAnorm")## Comparing coverage in peaks...## calcNormFactors has been renamed to normLibSizes
## calcNormFactors has been renamed to normLibSizes(Note that MAnorm would normally require to have a list of peaks for each sample/experiment).
Once computed, the normalization factors can be applied to an
EnrichmentSE object:
sm <- signal2Matrix(bwfiles, peaks, extend=1000L)## Reading /home/runner/work/_temp/Library/epiwraps/extdata/example_atac.bw
## Reading /home/runner/work/_temp/Library/epiwraps/extdata/example_atac.bw
sm <- renormalizeSignalMatrices(sm, scaleFactors=nf)
sm## class: EnrichmentSE
## 2 tracks across 150 regions
## assays(2): normalized input
## rownames(150): 1:195054101-195054250 1:133522798-133523047 ...
## 1:22224734-22224983 1:90375438-90375787
## rowData names(0):
## colnames(2): atac1 atac2
## colData names(0):
## metadata(0):The object now has a new assay, called normalized, which
has been put in front and therefore will be used for most downstream
usages unless the uses specifies otherwise. Note that for any downstream
function it is however possible to specify which assay to use via the
assay argument.
Obtaining normalization factors from the signal matrices themselves
It is also possible to normalize the signal matrices using factors
derived from the matrices themselves, using the
renormalizeSignalMatrices function. Note that this is
provided as a ‘quick-and-dirty’ approach that does not have the
robustness of proper estimation methods. Specifically, beyond providing
manual scaling factors (e.g. computed using
getNormFactors), the function includes two methods :
-
method="border"works on the assumption that the left/right borders of the matrices represent background signal which should be equal across samples. As such, it can be seen as an approximation of the aforementioned background normalization. However, it will work only if 1) the left/right borders of the matrices are sufficiently far from the signal (e.g. peaks) to be chiefly noise, and (as with the main background normalization method itself) 2) the signal-to-noise ratio is comparable across tracks/samples. -
method="top"instead works on the assumption that the highest signal (after some eventual trimming of the extremes) should be the same across tracks/samples.
To illustrate these, we will first introduce some difference between our two tracks using arbitrary factors:
sm <- renormalizeSignalMatrices(sm, scaleFactors=c(1,4), toAssay="test")
plotEnrichedHeatmaps(sm, assay = "test")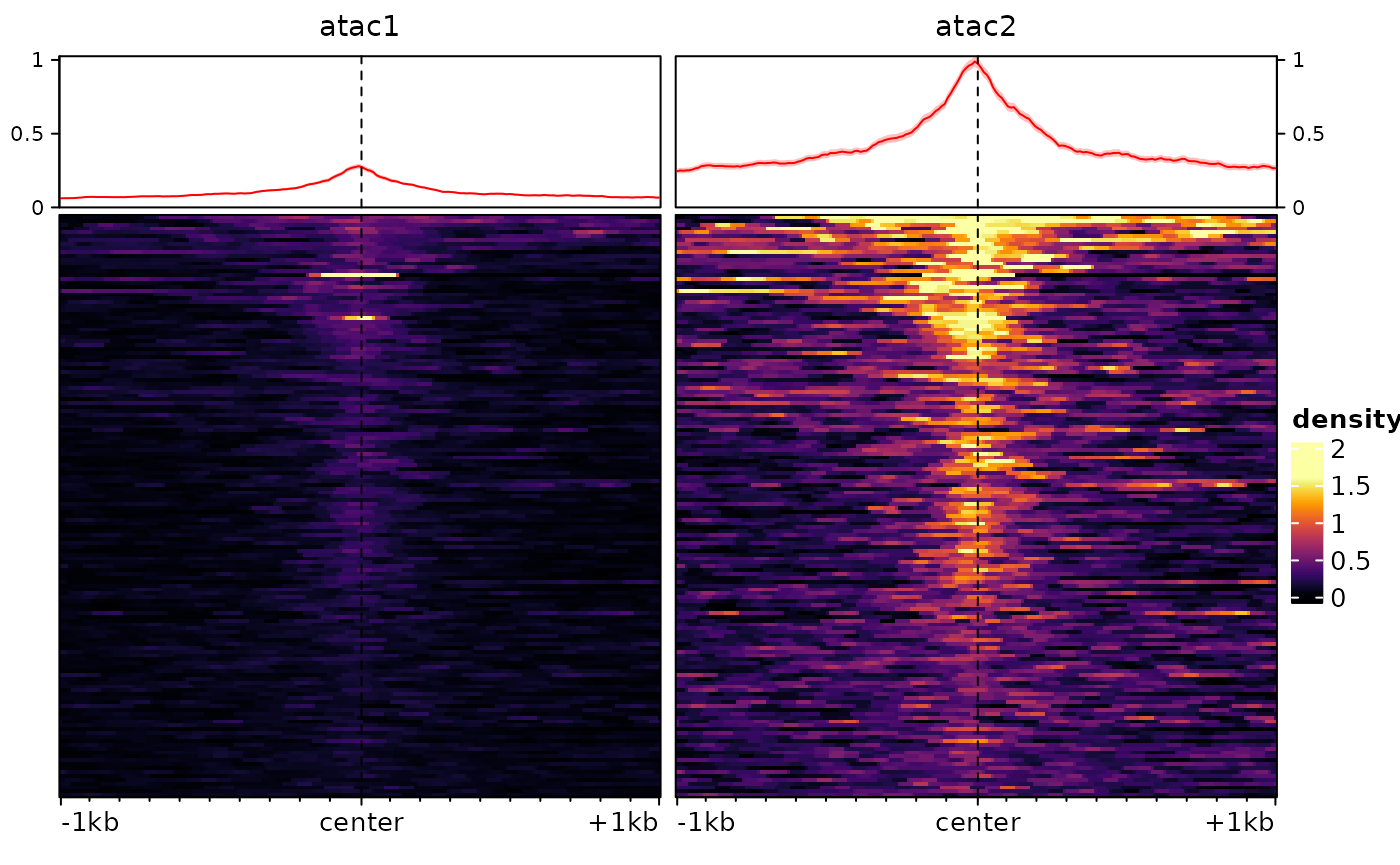
Then we can normalize:
sm <- renormalizeSignalMatrices(sm, method="top", fromAssay="test")
# again this adds an assay to the object, which will be automatically used when plotting:
plotEnrichedHeatmaps(sm)## Using assay topNormalized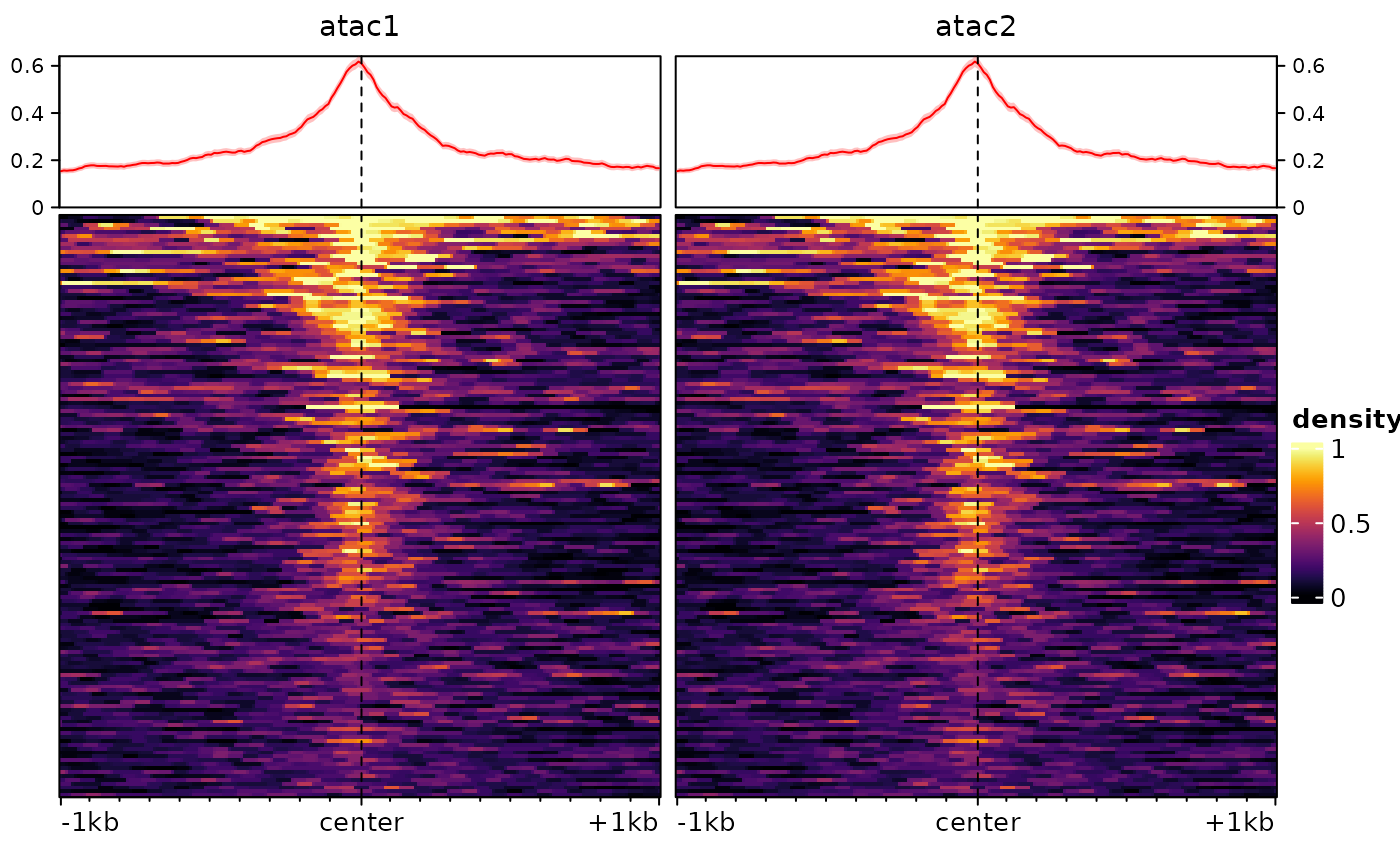
And we’ve recovered comparable signal across the two tracks/samples.
Session information
## R version 4.6.1 (2026-06-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] grid stats4 stats graphics grDevices utils datasets
## [8] methods base
##
## other attached packages:
## [1] epiwraps_0.99.122 EnrichedHeatmap_1.42.0
## [3] ComplexHeatmap_2.28.0 SummarizedExperiment_1.42.0
## [5] Biobase_2.72.0 GenomicRanges_1.64.0
## [7] Seqinfo_1.2.0 IRanges_2.46.0
## [9] S4Vectors_0.50.1 BiocGenerics_0.58.1
## [11] generics_0.1.4 MatrixGenerics_1.24.0
## [13] matrixStats_1.5.0 BiocStyle_2.40.0
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 rstudioapi_0.19.0 jsonlite_2.0.0
## [4] shape_1.4.6.1 magrittr_2.0.5 magick_2.9.1
## [7] GenomicFeatures_1.64.0 farver_2.1.2 rmarkdown_2.31
## [10] GlobalOptions_0.1.4 fs_2.1.0 BiocIO_1.22.0
## [13] ragg_1.5.2 vctrs_0.7.3 memoise_2.0.1
## [16] Rsamtools_2.28.0 RCurl_1.98-1.19 base64enc_0.1-6
## [19] htmltools_0.5.9 S4Arrays_1.12.0 progress_1.2.3
## [22] curl_7.1.0 SparseArray_1.12.2 Formula_1.2-5
## [25] sass_0.4.10 bslib_0.11.0 htmlwidgets_1.6.4
## [28] desc_1.4.3 Gviz_1.56.0 httr2_1.2.3
## [31] cachem_1.1.0 GenomicAlignments_1.48.0 lifecycle_1.0.5
## [34] iterators_1.0.14 pkgconfig_2.0.3 Matrix_1.7-5
## [37] R6_2.6.1 fastmap_1.2.0 clue_0.3-68
## [40] digest_0.6.39 colorspace_2.1-2 patchwork_1.3.2
## [43] AnnotationDbi_1.74.0 textshaping_1.0.5 Hmisc_5.2-6
## [46] RSQLite_3.53.2 filelock_1.0.3 httr_1.4.8
## [49] abind_1.4-8 compiler_4.6.1 bit64_4.8.2
## [52] doParallel_1.0.17 backports_1.5.1 htmlTable_2.5.0
## [55] S7_0.2.2 BiocParallel_1.46.0 DBI_1.3.0
## [58] biomaRt_2.68.0 rappdirs_0.3.4 DelayedArray_0.38.2
## [61] rjson_0.2.23 tools_4.6.1 foreign_0.8-91
## [64] otel_0.2.0 nnet_7.3-20 glue_1.8.1
## [67] restfulr_0.0.17 checkmate_2.3.4 cluster_2.1.8.2
## [70] gtable_0.3.6 BSgenome_1.80.0 ensembldb_2.36.1
## [73] data.table_1.18.4 hms_1.1.4 XVector_0.52.0
## [76] foreach_1.5.2 pillar_1.11.1 stringr_1.6.0
## [79] limma_3.68.4 circlize_0.4.18 dplyr_1.2.1
## [82] BiocFileCache_3.2.0 lattice_0.22-9 deldir_2.0-4
## [85] rtracklayer_1.72.0 bit_4.6.0 biovizBase_1.60.0
## [88] tidyselect_1.2.1 locfit_1.5-9.12 pbapply_1.7-4
## [91] Biostrings_2.80.1 knitr_1.51 gridExtra_2.3.1
## [94] bookdown_0.47 ProtGenerics_1.44.0 edgeR_4.10.1
## [97] xfun_0.59 statmod_1.5.2 stringi_1.8.7
## [100] UCSC.utils_1.8.0 lazyeval_0.2.3 yaml_2.3.12
## [103] evaluate_1.0.5 codetools_0.2-20 cigarillo_1.2.0
## [106] interp_1.1-6 GenomicFiles_1.48.0 tibble_3.3.1
## [109] BiocManager_1.30.27 cli_3.6.6 rpart_4.1.27
## [112] systemfonts_1.3.2 jquerylib_0.1.4 dichromat_2.0-0.1
## [115] Rcpp_1.1.1-1.1 GenomeInfoDb_1.48.0 dbplyr_2.6.0
## [118] png_0.1-9 XML_3.99-0.23 parallel_4.6.1
## [121] pkgdown_2.2.0 ggplot2_4.0.3 blob_1.3.0
## [124] prettyunits_1.2.0 jpeg_0.1-11 latticeExtra_0.6-31
## [127] AnnotationFilter_1.36.0 bitops_1.0-9 viridisLite_0.4.3
## [130] VariantAnnotation_1.58.0 scales_1.4.0 crayon_1.5.3
## [133] GetoptLong_1.1.1 rlang_1.2.0 KEGGREST_1.52.2