Generating bigwig tracks with bam2bw
Pierre-Luc Germain
Lab of Statistical Bioinformatics, University of Zürich;D-HEST Institute for Neuroscience, ETH Zürich, SwitzerlandSource:
vignettes/bam2bw.Rmd
bam2bw.RmdAbstract
This vignette documents the use of the ‘bam2bw’ function of the epiwraps package, which generates bigwig tracks from alignment files in an efficient and flexible fashion.
Introduction
The bam2bw function can be used to compute
per-nucleotide or per-bin coverage from alignments and save it to a
bigwig file. In this process, information about individual reads is
lost, but the produced signals are considerably more lightweight and
amenable to visualization. The bigwig format is readily queried from R
or compatible with a variety of tools, including genome browsers.
Many ways of compiling coverage
To introduce the different variations on coverage, let’s assume you’ve go the following single-end reads:
suppressPackageStartupMessages(library(epiwraps))
# we create some arbitrary genomic ranges
gr <- GRanges("chr1", IRanges(c(30,70,120), width=50), strand=c("+","+","-"),
seqlengths=c(chr1=500))
plotSignalTracks(list(reads=gr), region="chr1:1:180", extend=0, genomeAxis=FALSE)
For testing purposes, we’ll save this as a bam file and index it:
bam <- tempfile(fileext = ".bam") # temp file name
rtracklayer::export(gr, bam, format="bam")
Rsamtools::indexBam(bam)## /tmp/Rtmp3GAUBm/file37bd4a29f411.bam
## "/tmp/Rtmp3GAUBm/file37bd4a29f411.bam.bai"Using these example reads, we can illustrate different ways of computing coverages.
First, we can save coverage at different resolutions, from full resolution (each nucleotide is a single bin) to larger bin sizes, the latter giving smaller filesizes:
# Full coverage with bin width of 1 nucleotide (i.e. full resolution)
cov_full_bw1 <- tempfile(fileext = ".bw") # temp file name
bam2bw(bam, cov_full_bw1, binWidth=1L, scaling=FALSE)## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
# Full coverage with larger bins
cov_full_bw25 <- tempfile(fileext = ".bw")
bam2bw(bam, cov_full_bw25, binWidth=25L, scaling=FALSE)## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
plotSignalTracks(list(reads=gr, "binWidth=1"=cov_full_bw1, "binWidth=25"=cov_full_bw25),
region="chr1:1:180", extend=0)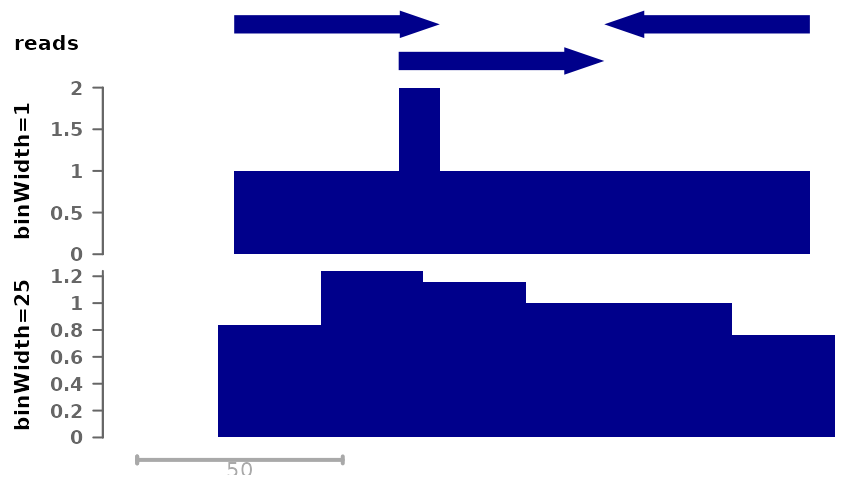
Both tracks compile the number of reads that overlap each position, but in the bottom track the signal is by chunks of 25 nucleotides. By default, the maximum signal inside a bin is used, however it is possible to change this:
# Using mean per bin:
cov_full_bw25mean <- tempfile(fileext = ".bw")
bam2bw(bam, cov_full_bw25mean, binWidth=25L, binSummarization = "mean", scaling=FALSE)## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
plotSignalTracks(list(reads=gr, "binWidth=1"=cov_full_bw1,
"binWidth=25\n(max)"=cov_full_bw25,
"binWidth=25\n(mean)"=cov_full_bw25mean),
region="chr1:1:180", extend=0)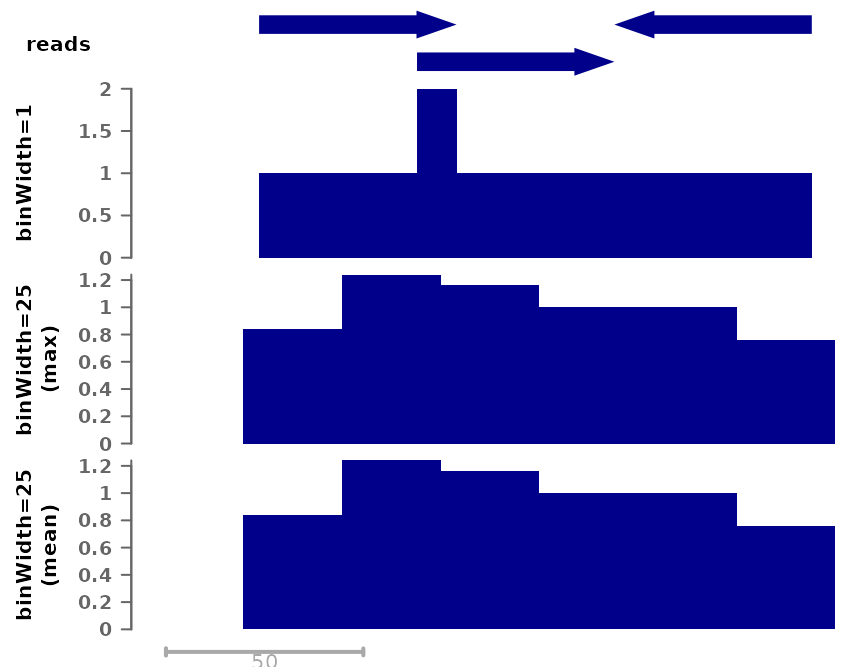
In most cases, single-end reads are just the beginning of the DNA
fragments obtained, and we know the average size of the fragments from
library prep QC (if not, see the estimateFragSize function,
or the simpler estimate.mean.fraglen function of the chipseq
package). It is therefore common to extend reads to this size when
computing coverage, so as to obtain the number of fragments (rather than
reads) coverage each position. This can be done as follows:
# Here the reads are 50bp, and we want to extend them to 100bp, hence _by_ 50:
cov_full_ext <- tempfile(fileext = ".bw")
bam2bw(bam, cov_full_ext, binWidth=1L, extend=50L, scaling=FALSE)## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
plotSignalTracks(list(reads=gr, "no extension"=cov_full_bw1,
"read extension"=cov_full_ext),
region="chr1:1:190", extend=0)
Taking into account read extension shows better the peak at the center, which is indicative of the fact that this is the region that was the most enriched in the captured fragments.
Instead of computing coverage, we could compute the number of reads starting, ending, or being centered at each position:
# Here the reads are 50bp, and we want to extend them to 100bp, hence _by_ 50:
cov_start <- tempfile(fileext = ".bw")
bam2bw(bam, cov_start, binWidth=1L, extend=50L, scaling=FALSE, type="start")## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
cov_center <- tempfile(fileext = ".bw")
bam2bw(bam, cov_center, binWidth=1L, extend=50L, scaling=FALSE, type="center")## `paired` not specified, assuming single-end reads. Set to paired='auto' to automatically detect.## Reading in signal...## Writing bigwig...
plotSignalTracks(list(reads=gr, "type=full"=cov_full_bw1,
"type=start"=cov_start, "type=center"=cov_center),
region="chr1:1:190", extend=0)
Note that when extending reads, as in this case, the position (e.g. “center”) are relative to the extended read (i.e. extension is applied first).
Example heatmaps created using different bigwig generation procedures
The following figure, created using epiwraps (see
the vignette on generating such
plots), represent chromatin accessibility (ATAC-seq) signals around
bound CTCF motifs in T-cells. The different signals are based on
different bigwig files derived from the same bam file using the
functions described above.
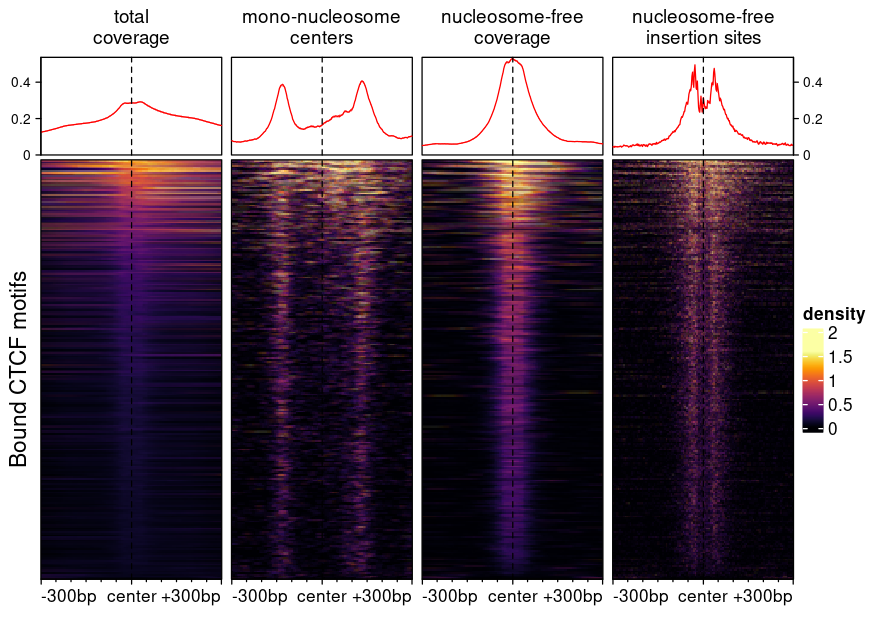
- The first heatmap (‘full coverage’) was generated with default parameter, and is the fragment coverage (i.e. how many fragments overlap any given location).
- The second heatmap shows the fragment of sizes compatible with
mono-nucleosomes, resizing fragments from their centers. The exact
arguments used were
minFragLength=147, maxFragLength=230, type="center", extend=25L. Using this we can see nucleosomes well-positioned at some distance from CTCF binding sites, but a relative depletion of nucleosomes at the bound site itself. - The third shows the coverage of nucleosome-free fragments, in this
case it was used with
maxFragLength=120. These are indicative of TF binding, and indeed we only see and enrichment in the center. - The fourth shows where the transposase inserted itself, and was
generated with
trim=4L, binWidth=1L, maxFragLength=120, type="ends". Using this we can see a nice footprint protected from the transposase by CTCF binding.
For more information about these parameters, see
?bam2bw.
ATAC fragment sizes convey rich information, but they are not perfect. For example, regions of DNA bound by multiple TFs can sometimes be captured as longer fragments which we would mistakenly classify as mono-nucleosome containing.
Working with fragment files as an input
If you use fragment files (preferably tabix-indexed) rather than bam
files as input, you can still perform most of the above tasks. See the
?frag2bw function for more information.
Session information
## R version 4.6.1 (2026-06-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] grid stats4 stats graphics grDevices utils datasets
## [8] methods base
##
## other attached packages:
## [1] epiwraps_0.99.122 EnrichedHeatmap_1.42.0
## [3] ComplexHeatmap_2.28.0 SummarizedExperiment_1.42.0
## [5] Biobase_2.72.0 GenomicRanges_1.64.0
## [7] Seqinfo_1.2.0 IRanges_2.46.0
## [9] S4Vectors_0.50.1 BiocGenerics_0.58.1
## [11] generics_0.1.4 MatrixGenerics_1.24.0
## [13] matrixStats_1.5.0 BiocStyle_2.40.0
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 rstudioapi_0.19.0 jsonlite_2.0.0
## [4] shape_1.4.6.1 magrittr_2.0.5 GenomicFeatures_1.64.0
## [7] farver_2.1.2 rmarkdown_2.31 GlobalOptions_0.1.4
## [10] fs_2.1.0 BiocIO_1.22.0 ragg_1.5.2
## [13] vctrs_0.7.3 memoise_2.0.1 Rsamtools_2.28.0
## [16] RCurl_1.98-1.19 base64enc_0.1-6 htmltools_0.5.9
## [19] S4Arrays_1.12.0 progress_1.2.3 curl_7.1.0
## [22] SparseArray_1.12.2 Formula_1.2-5 sass_0.4.10
## [25] bslib_0.11.0 htmlwidgets_1.6.4 desc_1.4.3
## [28] Gviz_1.56.0 httr2_1.2.3 cachem_1.1.0
## [31] GenomicAlignments_1.48.0 lifecycle_1.0.5 iterators_1.0.14
## [34] pkgconfig_2.0.3 Matrix_1.7-5 R6_2.6.1
## [37] fastmap_1.2.0 clue_0.3-68 digest_0.6.39
## [40] colorspace_2.1-2 patchwork_1.3.2 AnnotationDbi_1.74.0
## [43] textshaping_1.0.5 Hmisc_5.2-6 RSQLite_3.53.2
## [46] filelock_1.0.3 httr_1.4.8 abind_1.4-8
## [49] compiler_4.6.1 bit64_4.8.2 doParallel_1.0.17
## [52] backports_1.5.1 htmlTable_2.5.0 S7_0.2.2
## [55] BiocParallel_1.46.0 DBI_1.3.0 biomaRt_2.68.0
## [58] rappdirs_0.3.4 DelayedArray_0.38.2 rjson_0.2.23
## [61] tools_4.6.1 foreign_0.8-91 otel_0.2.0
## [64] nnet_7.3-20 glue_1.8.1 restfulr_0.0.17
## [67] checkmate_2.3.4 cluster_2.1.8.2 gtable_0.3.6
## [70] BSgenome_1.80.0 ensembldb_2.36.1 data.table_1.18.4
## [73] hms_1.1.4 XVector_0.52.0 foreach_1.5.2
## [76] pillar_1.11.1 stringr_1.6.0 circlize_0.4.18
## [79] dplyr_1.2.1 BiocFileCache_3.2.0 lattice_0.22-9
## [82] deldir_2.0-4 rtracklayer_1.72.0 bit_4.6.0
## [85] biovizBase_1.60.0 tidyselect_1.2.1 locfit_1.5-9.12
## [88] pbapply_1.7-4 Biostrings_2.80.1 knitr_1.51
## [91] gridExtra_2.3.1 bookdown_0.47 ProtGenerics_1.44.0
## [94] xfun_0.59 stringi_1.8.7 UCSC.utils_1.8.0
## [97] lazyeval_0.2.3 yaml_2.3.12 evaluate_1.0.5
## [100] codetools_0.2-20 cigarillo_1.2.0 interp_1.1-6
## [103] GenomicFiles_1.48.0 tibble_3.3.1 BiocManager_1.30.27
## [106] cli_3.6.6 rpart_4.1.27 systemfonts_1.3.2
## [109] jquerylib_0.1.4 dichromat_2.0-0.1 Rcpp_1.1.1-1.1
## [112] GenomeInfoDb_1.48.0 dbplyr_2.6.0 png_0.1-9
## [115] XML_3.99-0.23 parallel_4.6.1 pkgdown_2.2.0
## [118] ggplot2_4.0.3 blob_1.3.0 prettyunits_1.2.0
## [121] jpeg_0.1-11 latticeExtra_0.6-31 AnnotationFilter_1.36.0
## [124] bitops_1.0-9 viridisLite_0.4.3 VariantAnnotation_1.58.0
## [127] scales_1.4.0 crayon_1.5.3 GetoptLong_1.1.1
## [130] rlang_1.2.0 KEGGREST_1.52.2